Detecting unreliable predictions of machine learning models
Interview with Giovanni Cinà, researcher on Methods in Medical Informatics
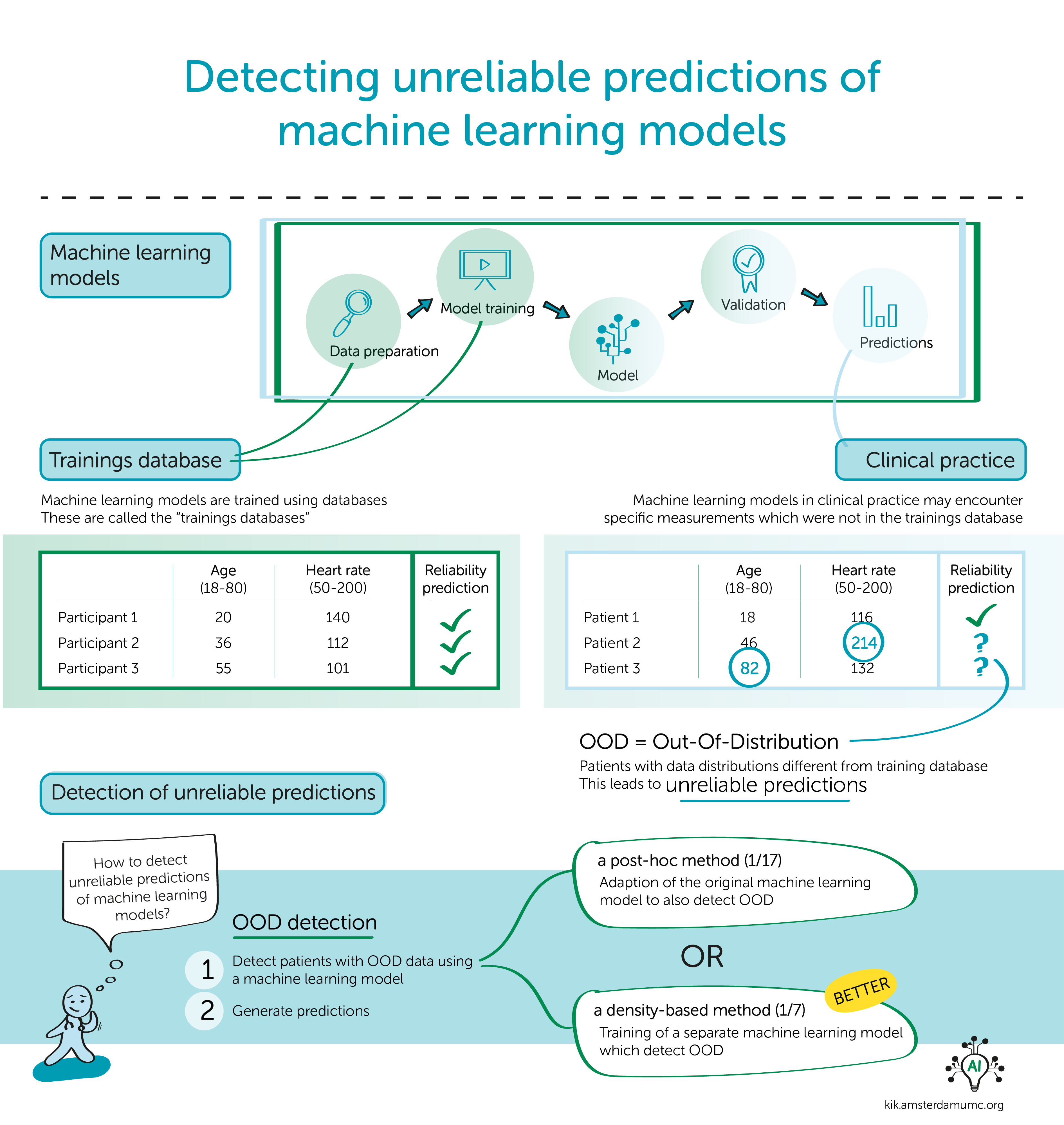
More and more people are working on developing a prediction model with machine learning techniques. However, these models may give unreliable predictions in clinical practice. It is important to detect predictions that are not reliable. Giovanni Cinà conducts research on detecting these unreliable predictions.
Why can machine learning models give unreliable predictions in clinical practice?
In clinical practice, the data of patients changes constantly. This could be due to the patients themselves changing - e.g. an ageing population - but also to changes in the care protocol or the IT infrastructure. When we train a machine learning model, we measure its performance on the training data distribution. When the same model is applied to data distributed differently, we cannot assume it will perform in the same way. As a consequence, sooner or later an implemented model will find itself predicting 'outside of its comfort zone'.
How do you detect these unreliable predictions?
We do not detect unreliable prediction themselves, but instead try to detect patient data that is 'novel' with respect to training data. On these patients the predictions are probably not reliable, so we want to prevent giving misleading information to the clinicians and abstain from giving a prediction. Detecting these different data points is called Out-Of-Distribution (OOD) detection.
Can you explain the two different methods that can be used for OOD detection?
One approach is to take the prediction model for the main task (for example: mortality prediction) and tweak it in such a way that it also signals when a data point is OOD. This is the post-hoc method. Another approach consists on training a separate model for the purpose of OOD detection; usually the latter model attempts to capture the distribution of training data and, when a new data point becomes available, checks if the data point is likely to come from the training distribution. This is the density-based method.
What are your future plans?
Our plan is to improve the safety profile of machine learning models applied in healthcare by adding an OOD detection module to them. This is already done with Pacmed's product running in the Intensive Care at OLVG, and we are planning to apply this technique to many other implemented models at the Amsterdam UMC and beyond.
Curious and what to read more?
Mohammad Azizmalayeri, Ameen Abu-Hanna, Giovanni Ciná. Unmasking the Chameleons: A Benchmark for Out-of-Distribution Detection in Medical Tabular Data.